Contents
1. Why data management is so important
2. How many data?
3. Observational unit identification
4. Recording data
5. Data management software
6. Spreadsheet design
7. Computer data entry
8. Data validation
9. Missing values
10. Data manipulation
11. Multiple-level data structures
12. Screen display
13. Data retrieval
14. Reporting
15. Backing up and audit trails
16. Documentation and archiving
17. Other types of data
18. Ensuring good data quality
19. Ethical considerations
20. Related reading
The importance of ensuring good study design as discussed in the previous Study design guide cannot be overemphasised. If the design of the study is inadequate and the data produced for analysis have little chance of meeting the desired objectives then the study will be wasted.
The discipline of biometrics is often viewed as having two components - study design and statistical analysis - but this an oversimplification. There are other components in the research process as described in the six teaching guides. The one that is often overlooked, but one that is as important as any other, is that of data management. This is the component that can take the most time and, if not attended to carefully, can lead to errors in data recording, computer entry, storage and management that can spoil the subsequent statistical analysis.
Data are often expensive to collect. There is no point, therefore, in putting a lot of effort into making sure that the methods used for obtaining the data are of high scientific analytical quality if the same stringent quality controls are not maintained during data recording and computer entry.
Procedures in data management begin at the start of the study design stage and cover the following range of activities:
It can be seen that these activities begin right at the beginning and finish when everything else is completed. Thus, the whole data management process, even that of archiving, needs to be planned at the start of the project. Indeed, unless proper attention is paid to this subject it is easy to make mistakes and reach wrong conclusions. Much of what is discussed in this guide is described in greater detail in the Good practice guides dealing with data management and written by the University of Reading Statistical Services Centre. It is recommended that these be read.
Some aspects of data management, such as data entry and verification, documentation and archiving, are often seen to be boring. But others, such as data system design, data handling and programming can be as interesting as other statistical topics covered under Study design and Statistical modelling.
By studying the illustrations used in several of the case studies and tackling the study questions related to data management issues the student can learn the practicality of good data management and appreciate its importance in his/her future career. A number of questions are included within the case studies to help bring this topic alive.
Data management is time consuming. It is therefore essential that plans are drawn up at the outset to set milestones for the completion of each task, and to ensure that the necessary resources are in place to meet these objectives.
Many projects are now funded to be completed within a given time-frame. Data entry can be particularly time-consuming and estimates need to be made on the number of data items that will be involved in computer entry and the length of time envisaged to do this. The actual time involved will invariably be more than estimated. Case Study 6 (a longitudinal participatory study with farmers) and Case Study 11 (a livestock breed survey) both suffered from underestimates of the time required for computer data entry.
Having designed a questionnaire or data recording sheet it is a good idea to prepare some dummy data to time how long it takes to enter the data into the computer. Then
The time to be taken to do a job of work is often underestimated. As indicated in the last bullet above 'doubling the first estimate' is often a good rule of thumb.
Having estimated the time that is likely to be involved one can then calculate the length of the job from the total number of hours anticipated, and the number of people to be used in data entry and checking. A question is included in Case Study 9 in which a student is asked to enter a set of data into a spread sheet to calculate how long it takes and, thence, estimate the total time required to enter all the data.
Practical exercises such as this will bring home to the student the time-consuming aspects of data management and the importance of deciding how many data should be collected in the first place, both in terms of the total sample size and the number of variables recorded per sample. Study design and data management are thus closely linked. There are several sets of data included within the case studies that can be used by the student to evaluate data entry schedules.
Decisions will also be required on whether additional computer programming is necessary, whether interim reports are required at strategic times during the course of a project and for whom they may be required. For example, haematological and parasitological data collected in a clinical trial may need to be summarised, not only to report on the results at the end of the experiment, but also to monitor the health of individual subjects as the experiment progresses. The suitability of alternative data storage systems may need to be considered to ensure simple but regular data retrieval.
It may be that the estimates suggest that the quantity of data to be collected may be too large to handle with existing resources. If so, consideration should be given to reducing the number of variables to be measured or reducing the overall size of the study.
Certainly, there is a tendency in survey work to collect more data than are warranted, and it is tempting to use the opportunity to collect as much information as possible. As discussed in Study design it is important when planning a study to ensure that only those data, which are relevant to the objectives of the survey and the hypotheses to be evaluated, are collected.
An example is provided in Case Study 11. This case study describes a livestock breed survey, which had clear and precise objectives to collect data on numbers of animals belonging to different species, their management and their breed characteristics so that the results might be used for determining future breeding objectives for Swaziland. When the design of this survey was first being developed it was tempting to use the opportunity to collect additional household socio-economic data. Fortunately, the researchers resisted such requests and confined their attention only to questions directly related to the aims of the survey. Even so the quantity of data that was collected and needed to be entered into the computer was greater than had been appreciated.
In summary, a researcher must ensure that as far as possible only data pertinent to the objectives of the study are collected so as to ensure that computer entry can be done within the required time-frame. Good filing systems, well designed data sheets and questionnaires, as discussed later, will help with the overall efficiency.
Each observational, sampling or experimental unit needs a unique identifier. In an experiment or an observational study it may often be wise to give two separate identifiers to the main units under investigation, such as a plot in a field or an animal, just in case one identifier is lost.
Case Study 10 describes how village cattle, monitored during a trial to investigate the impact of tsetse control on animal health and productivity were given two ear tags with different identifications codes. Thus, should an animal lose one of the tags, it can still be identified from the other until the missing tag is replaced.
Case Study 5 describes randomised block experiments used to evaluate agronomic and morphological characteristics of Napier grass accessions. Errors can occur in such an experiment when endeavouring to maintain correct sample identification during the process for harvesting the crop, separating the leaves from the stems and measuring quantities of material for assessment of dry matter yield. For this reason both accession and plot numbers were used foridentifying samples during harvesting and processing so that there is double identification throughout. If at any time two samples are mistakenly recorded with the same accession number, it is then an easy matter to correct the error by looking at the plot number.
Case Study 5 also provides an interesting example of other problems that might need to be dealt with in plot identification. White pegs used in the field experiment were often mistaken for bones by hyenas prevalent in the area. Unpainted pegs were better but were still 'attacked' sometimes. Metal pegs were not a suitable alternative for local residents can find them useful and they sometimes disappear. The only alternative that seemed possible was to tie plastic write-on labels onto the plant stems, but this made the reading of the of the plot numbers more difficult. Such problems associated with research methods come under Study design but the consequences for data recording are apparent.
Having decided on the measurements to record, a data recording sheet then needs to be designed that not only allows data to be recorded easily on it but is prepared in such a way that computer entry is straightforward. We shall assume for now that we are dealing with a simple study, such as an experiment in a controlled environment or an on-station study, which has a simple data structure and for which the data are collected from a single layer of observational units. We shall deal later with more complicated multi-layer structures such as surveys.
Firstly we shall assume that a data recording sheet has been prepared in the form of a grid and that the measurements for the different variables are being entered in different columns with the measurements recorded for each observational unit entered in rows. It is important that the code that uniquely identifies the observational unit is written in the first column, or first two if more than one code is being used (see Video 1 linked with Case Study 10). In the case of a designed experiment the plot number code would be recorded here. The next few columns in the recording sheet should be reserved for any blocking or treatment codes that are associated with the observational unit and included within the study design.
When preparing the recording sheet the researcher should make sure that there is ample room within each row and column to allow data values to be clearly written so that they can be read easily. How often do we find in everyday life having to fill in a form for which there is insufficient space to write the information requested? If there is insufficient space the person recording the data will be forced to cramp his/her writing with the consequential danger of mistakes occurring in computer entry due to illegibility.
As far as possible, data should be written directly onto the sheets to be used for data entry, not first copied from a recording sheet used in the field onto a master sheet in the office or laboratory. Indeed, data should never be transcribed from one piece of paper to another, for this is a time when mistakes are commonly made. The data entry person should be able to key directly from the original recording sheet, however dirty it may have got from having been dropped in the mud or been smeared with animal faeces. The use of indelible ink is normally recommended, not pencil that can be rubbed out, or water soluble ink. When a wrong figure is written, the mistake should be marked and the correct value written alongside. Recording sheets should be filed or bound together so that they do not easily get separated.
Sometimes measurements made by certain scientific analytical equipment will be produced directly onto paper, diskette or computer. Steps need to be taken to transfer these data separately to the appropriate computer file. Again they should not be transferred manually onto a master data recording sheet - they should be transferred direct into the computer and organised there.
It is thus the responsibility of the researcher to consider at the study design stage how data will be collected. He/she must ensure that the data are recorded in such a way that they can be entered into the computer directly from the sheets on which they are recorded. Case Study 1 illustrates the types of problems that emerged when this was not taken into account for a particular questionnaire designed to collect information from households on milk consumption.
Case Study 14 demonstrates various difficulties and hazards that arose when insufficient planning took place into how data could best be laid out on the recording sheets.
There is no need to do calculations by hand - these are better done by computer. For example, if animal body weights are measured on different days, then, provided that dates are also recorded, daily weight gain can simply be calculated as (weight2 - weight1) / (date2 - date1). A column does not need to be reserved in the recording sheet for weight gain to be calculated; this can be calculated later directly by the computer.
Decisions need to be made before the study begins on how many decimal places to record. These should be related to the precision of the measuring instrument, e.g. a weighing balance, or to the numbers of decimal places that make biological sense. There is nothing more irritating than reading or entering a column of data with varying numbers of decimal places. When the last digit is a zero this should be written as such, not omitted. For example, if one decimal place is being recorded for a given variable then the value 21, say, should be recorded as 21.0, not 21. These problems are illustrated in Case Study 15 - a field experiment comparing the effects of seeding rate and fertiliser level on the performance of two dry bean cultivars.
Sometimes variables are collected that require some method of scoring, e.g. extent of pest damage, animal condition. A range of scores need to be defined in advance. Different levels for classification variables will also have been defined. It is often easier to code these as numeric integers for these are easier to enter than alphanumeric values. Once the data are stored it is an easy matter to use statistical software to redefine the levels into more informative codes. Most software packages have easy data handling facilities to do this.
When designing a recording sheet for a study which involves more than one measurement in time, a decision first needs to be made as to whether the measurements can be recorded in a standard order or not. For example, recordings of yields from plots in a crop experiment, or measurements of body weights made in a controlled, penned, animal feeding experiment are likely to be done in the same order each time. This is because field plots or animal pens remain fixed in space. This cannot be done, however, when a herd of cattle is being monitored, since animals will reach the crush in a 'random' order (see Case Study 10)
When data are to be collected in a fixed order, details of the study layout and the plot or pen identifications can be printed in the data recording sheet in advance. Case Study 16 illustrates how GenStat can be used to do this for a factorial experiment. This cannot be done , however, when observational units are likely to be recorded in any order.
When there is more than one sampling occasion it is recommended that a fresh blank recording sheet be used each time, from which the data can be either entered into a new spreadsheet in the computer or into a data base management system especially written for the purpose. The researcher may wish to see data obtained on different sampling occasions listed alongside each other: for example, weights and blood packed cell volumes in a cattle vaccine experiment (see page 5 of Biometrics Unit, ILRI (2005)). As described later, it is easy to copy data from the individual spreadsheets to a master spreadsheet so that measurements taken on different dates can occur side by side.
Much of the forgoing applies also to the design of questionnaires, for example, making sure that there is ample space on the questionnaires to allow answers to be written, and deciding on units for recording quantitative data and the numbers of decimal places to record. The question of questionnaire design is addressed in Study design. Further mention of questionnaire presentation is included under Screen display.
To summarise:
One of the first decisions is to decide on the appropriate software to use. University of Reading Good practice guide No. 10 has been written to help researchers and research managers to decide whether the use of a relational database package such as Microsoft Access is needed for the management of their data. This will depend on the complexity of the study and the different types of observational units at different hierarchical levels. So far we are considering simple data structures, essentially at one layer. The different types of software that can be used for handling such data include:
Geographic information systems are also available for storing spatial data.
Some of the advantages and disadvantages of the three types of packages for data management are given in the following table.
Package |
Advantages |
Disadvantages |
Statistical |
Data management and data analysis can be done within the same package. |
Usually unsuitable for multi-level data structures |
Can do most that a spreadsheet package can do. |
Lacks security of a relational database management system. | |
Will usually have programming capabilities. |
Graphical facilities may not be as good as in specialised graphical software. | |
Spreadsheet |
User friendly, well known and widely used |
Unsuitable for multi-level data structures |
Good exploratory facilities |
Lacks security of a relational database management system | |
Statistical analysis capabilities limited to simple descriptive methods | ||
Database management |
Secure |
Needs computer expertise in database development |
Can handle complex multi-level data structures |
Graphical facilities may not be as good as in specialised graphical software. | |
Allows screen design for data input |
Statistical analysis capabilities limited to simple descriptive methods | |
Will generally have standard facilities for reporting |
Each type of package has its own special use. Nevertheless, statistical, spreadsheet and database management packages have overlapping facilities for data management, and all can now 'talk' to each other. In other words a data file stored in one package can be exported (transferred) to another. The researcher needs to anticipate at the start of a project how data entry, management and analysis will proceed, and plan accordingly.
Excel is popular among researchers and is suitable for storing data from simple studies. But care is needed in handling spreadsheets as it is easy to make mistakes. Excel does not offer the same data security as a data base management system and so it is easy to lose and spoil data.
CSPro (Census and Survey Processing System) is a powerful general software package for survey work - see Software. A particularly useful feature is the facility for the creation and editing of computer screens for date entry.
There is no reason nowadays why data entry, management and analysis cannot all be done in the one statistical package, especially for the more simple studies in which data can be stored in standard spreadsheets. The problems of data security remain but the advantage, as indicated in the above table, is that all the stages from data entry to analysis and interpretation can be done within the same package.
This guide promotes the idea that the teaching of all aspects of data handling and analysis should focus first on the use of a single statistical package. This could be a useful approach to teaching and mean that data management is taught as part of the study design - data analysis framework. It could increase the relevance of data management to the student and make the subject more interesting. Think about it.
Once all the data handling facilities of a statistical package have been exhausted attention can then be turned to Excel or another spreadsheet package to see what additional facilities are available there. Finally, the use of more specialised data base management software for handling the multi-level datasets on which some of the case studies are based (e.g. Case Study 10 and Case Study 11) can be taught.
The advantage of this approach is that the student can find out what data handling facilities are available within the statistical package itself. This means that the package will be taught not just as a statistical tool but as a data handling tool too. The student will not have to move from one package to another with the risk of making mistakes. At the end of the course the student will be able to grasp better the appropriate roles for each type of package in the data handling and management process.
Since most of the case studies use GenStat to demonstrate methods of analysis we shall start by using this package to illustrate some of the data handling facilities that are possible in a statistical package. When data handling facilities are not available in GenStat, mention is made of features available in Excel or database management software.
A spreadsheet can be viewed as a simple two-way grid structure usually with rows representing the observational units and columns containing values for the observed variables. It is advisable that the first column (C1 in GenStat) be reserved for the identification code for the observational unit (Fig. 1).
Fig. 1 Blank GenStat spreadsheet.
The next columns (C2, C3, ... ) should be used for classification variables (treatments, factors, other attributes). These can then be followed by variables that might be used as covariates (e.g. sex, age, initial weight) with the remainder of the columns for the measurements for the variables to be analysed. Each column should be headed with a suitable, descriptive name (not C1, C2, C3, ... ).
Case study 3, a comparison of health and productivity of Dorper and Red Maasai sheep, illustrates how further information can be added to the top rows of the spread sheet to provide more details of the contents of the variables. This is discussed later under Documentation and archiving.
Sometimes other methods for arranging the data may be more appropriate. Case Study 9 provides such an example. It describes a laboratory experiment to determine optimum germination of pollen grains of a leguminous tree species Sesbania Sesban. Fifteen sets of germination values were collected for eight sucrose concentrations from six buds in pairs of replicates for three different sizes of buds. The fifteen germination values were obtained by counting pollen grains in 15 different fields viewed under a microscope.
As these germination values were being recorded on the same occasion, it was considered easier to record the data for this experiment with the 15 germination values entered across the spreadsheet with each of the other factor levels written down the sheet.
When observations are made at only one point in time all variables can be entered into the same spreadsheet. When the measurements are repeated in time, however, the researcher may prefer to have measurements for separate variables on separate sheets so that he/she can observe changes in values over time across the spreadsheet. It is best, however, to enter the data collected on each occasion into a new blank spreadsheet and then to transfer individual columns onto these working sheets. The columns that contain observational unit identification, classification variables and covariates could likewise be stored on a separate master sheet and copied to each spread sheet as necessary.
Statistical packages generally require that all the measurements that are to be analysed for a variable are stored in one column. Thus for a split-plot in time repeated measurement analysis all the values will need to be copied into one column. This presents no problem for GenStat. Data stacking and unstacking methods are illustrated in Case Study 9, a form of multi-level design, and Case Study 11 for the analysis of livestock activities undertaken by different members of a homestead in Swaziland.
To summarise how the handling of data from a longitudinal study might be approached.
Careful design of the spreadsheets to hold the data can facilitate later data analysis and archiving. This will facilitate documentation of the data too. To the right of the area reserved for the measured variables can be another area to contain additional variables calculated from the raw measurements. It is recommended, however, that the input spreadsheets be saved before any calculations are done and the modified spreadsheets saved under separate names. This will prevent risks of mistakes occurring that may result in the original data becoming corrupted.
Finally, it is important that the researcher develops a systematic and consistent method for naming the various spreadsheets. When more than one version of a spreadsheet is kept it should be clear from its name which version it is. The date when a spreadsheet is created can often be usefully incorporated within the naming method.
From now on we shall assume that we have established our case for a progressive approach in the teaching of data management: statistical package (say, GenStat) → spreadsheet package (say, Excel) → data base management package (say Access).
Thus, starting with GenStat, the need for a skilled, experienced data entry person will depend on the nature and volume of the data to be entered. For small data sets the researcher may be happy to enter the data him/herself or to alternatively use his/her research technician. There are advantages in this in that the researcher or technician will be able to spot obvious errors and deal with them directly. The need for skilled data persons is likely to become more apparent for survey data when the volumes of data are likely to be large.
It is important to establish rules for data entry, especially when the task of data entry is delegated. It is advisable, for instance, that the data entry person types exactly what is recorded and does not alter anything even if he/she realises that something is wrong. When a value looks strange it is much better that it is highlighted on the data sheet and that the researcher checks it later.
Verification of data entry is important. This is ideally done by a data entry person reentering the data from the recording sheet into the computer and being alerted when a mismatch occurs. If possible, verification should be done by someone other than the person who entered the data. An individual is often inclined to repeat the same mistakes.
GenStat has a simple verification facility. Data verification can also be done in Excel, although in a little more cumbersome way by entering the data twice into two worksheets, setting up an additional blank worksheet and applying the DELTA function to corresponding cells in the first two worksheets. When two values are compared with this function a 1 is entered in the third sheet if they are the same and a 0 if not. Alternatively the IF function can be used to return 0 if cells are equal and 1 if they are not. Database management systems can similarly be programmed to provide a verification facility.
Data verification is time consuming. Often projects do not allow sufficient resources to allow time for the data to be entered twice. As an alternative, a listing of the input data is sometimes printed and used to compare each input value by eye against the corresponding value in the original recording sheet. This, however, is not reliable. It is easy to lose patience. Except for the smallest data sets, it should not be encouraged.
Procedures to be undertaken for data entry and verification need to be agreed and budgeted at the planning stage and a person identified to be made responsible for supervising the work. Procedures for incorporating data that are automatically stored in other forms of computer media need to be planned at the start too.
Finally the reader is referred some of the University of Reading Good practice guides on data management. Guide 3, for example, describes how a spreadsheet package can be used effectively for data entry provided that "great care" and "rigour and discipline" are applied. Guides 6 and 7 show how, in more general terms, to set up, implement and manage a data entry system. CSPro is used to illustrate the process.
It is helpful to detect unusual values during the data entry phase, especially for complex data sets. This may, for instance, be due to errors in writing down the values when recording the raw data.
The simplest approach is to set upper and lower values within which it would be biologically reasonable to expect the data to lie. This is not routinely possible in GenStat (except by writing data checking procedures once the data have been entered). Excel, on the other hand, does have a simple validation facility that can allow upper and lower limits to be defined for whole numbers, decimal numbers and dates, set limits to the lengths of text and calculate values for formulae to determine what is allowed.
Similar facilities to capture errors during data entry can be programmed into relational data base management systems.
As well as handling multi-level data structures, such as arise in surveys, data base management systems are also especially suited for handling data collected during longitudinal studies when different types of data are recorded. For instance, data on certain events that take place during the study may be required in addition to the routinely recorded measurements that occur at regular intervals. For cattle, for example, this could include information on dates of calving, dates of weaning, dates of treatments, dates of disposals and so on.
A database management system is able to manage and assemble data in several files simultaneously, and so data validation checks, such as checking that intervals between successive calvings fall within reasonable limits or that a date of disposal does not occur while measurements are still being recorded on the live animal, can be readily programmed.
When measurements are made in random order over time, (see, for example, Case Study 10 and Video 1), it is important to ensure that each plot or animal code that is entered from the recording sheet (along with the measurements for the monitored variables) matches one of the permitted plot or animal codes previously stored in a master file within the data system. As noted in Case Study 10 (which deals with longitudinal collection of data in a herd monitoring scheme) comprehensive checking of errors of this type can save a lot of work later.
A livestock data base management system LIMMS, written by the International Livestock Centre for Africa (one of the two institutes merged to form ILRI) provides a comprehensive system for handling livestock data (Metz and Asfaw, 1999). It is written in dBase.
Many recording errors can be captured during data entry. However, some may escape. Once data entry is complete a variety of summary tables, box plots, histograms or scatter diagrams, as discussed in the Exploration & description guide, can be produced to identify potentially extreme or unusual values that fall within the preset limits, but nevertheless fall outside the distribution shown by the majority of values for the other observational units. These values should first be checked against the original raw data to see whether there has been a mistake in data entry.
If the value is the value written on the recording sheet the researcher will then need to decide what to do. The decision will be based on biological considerations. If a data value is changed in the database then a note should be made to that effect in a recording book or in a separate spreadsheet. Case Study 7 deals at length with the need to keep an audit of corrections made to rainfall records retrieved from different sources of rainfall data in Zambia and describes how records of changes made to the data are kept. A log of modifications to the data set is also kept by Case Study 6.
Statistical and spreadsheet packages contain good exploratory techniques and it is sometimes preferable to transfer data files from a database management system to one of these packages to commence the analytical phase.
Excel has procedure known as the 'pivot table' facility that allows data to be tabulated in different ways. This is an attractive and easy-to-use facility. As well as being able to calculate means and frequency totals, the tables can be used to highlight unusual values. For example, by creating tables of frequency counts checks can be made of potential errors in coding of classification variables. A count other than 1 in a cell in a two-way pivot table by block x treatment for a randomised block could signify that the code for a particular plot had either been omitted or entered incorrectly.
This can similarly be done using statistical, spreadsheet or database management packages, but Excel has the additional feature whereby, on clicking a cell of particular interest, the observational units that contributed to the contents of the cell are displayed. An illustration of the use of the pivot table facility for summarising and checking data for analysis is given in Case Study 8, a feeding experiment for goats.
A log book is recommended to keep a record of all data handling events, including the dates when data were first entered into the computer and when they were verified. If data values are altered from those recorded on the data sheet then these should also be noted. In this way the researcher, at any subsequent time during statistical analysis or writing up, can look to see what changes may have been made to the data. He/she will then be able to see what influence any alterations of the data may have had on the results. The need for keeping such logs is often overlooked. Although tedious it is an essential ingredient of good data management and should be budgeted for at the planning stage.
Data may sometimes be missing. An animal may be ill during routine herd monitoring and kept behind at the homestead, or an animal may die. Some plants may fail to grow (see Case Study 16) or a plot in an experiment may be destroyed. There may be a fault in analytical equipment or a sample is mislaid.
Decisions need to be made on how to record such missing observations. One solution is to leave the data field blank. However, it should be remembered that a 'blank' may be expected to be different from the value zero and that a computer program may not distinguish between them. Packages sometimes use a '*' to signify a missing value. Alternatively, an unusual value, e.g. -9999, can be stored. Provided a consistent method of definition is followed during data entry, it will always be possible to recode missing data later to suit a particular software package. The method used for identifying a missing value should be documented.
GenStat has a useful facility whereby a cell can temporally be defined as missing, yet retaining the original value so that it can be recalled later. This is particularly useful in analysis of variance for balanced designs where deleting a record can cause an experiment to become unbalanced, whereas temporally specifying an observation to be missing allows the record to be retained and the balance maintained.
GenStat often identifies potential outliers or observations exerting particular influence on the results of analysis (see, for example, Case Study 1 in which a number of points are identified as having special influence on the slopes of a regression line). By temporally allowing these values to be missing analyses can be rerun to see what the results look like without them.
Data management does not necessarily stop when all the data have been entered and checked. As discussed in the Exploration & description guide patterns in the data often need to be explored. This can be through summary tables or scatter or histogram plots. Summary tables of totals or means may require to be prepared for subsequent analysis.
Data exploration and analysis will often require careful data handling. This is where good data management skills become an asset. As well as deciding how to store the data and what software to use, it is also important to know at the outset which package is to be used to handle the data manipulations that may be necessary. The different types of data manipulation facilities that are likely to be needed are listed below.
We have recommended that the teaching of data handling and analysis should focus first on exploring the range of facilities available within the statistical software package being used in the course. Once these have been fully explored the student can then look at alternative ways for handling the data when using a spreadsheet package. We are still considering simple studies with simple data structures for which data can be handled in simple spreadsheets. We shall discuss multi-level data structures later.
As GenStat is the primary statistical package associated with the case studies we shall focus on the facilities available in GenStat. However, many will also feature in other statistical packages. Many of the following topics are common data handling tasks and the different sections provide hints on how to accomplish them effectively.
As has already been mentioned calculations needed to derive variables from the raw data are best done by computer. This saves errors in calculation. Case Study 13 lists many variables to be measured on slaughter of goats. A few of these can be derived after the others have been entered into the computer. Other case studies also demonstrate how new variables are derived from the input variables.
GenStat also has data manipulation features that allow the formation of new groupings from existing values, such as ages of experimental subjects. GenStat distinguishes variables that are used to classify other variables and refers to them as 'factors'. Sometimes variables need to be used in either form, as a factor or variable (referred to by GenStat as 'variate'), and this is allowed.
GenStat also has the useful facility whereby factor levels that occur within definite patterns (e.g. treatment order within blocks) can be entered using a shortcut method that describes the pattern.
Most of the calculations needed to derive new variables can be done within the dialog box facilities of GenStat. In some cases a series of programming steps are necessary. The flexibility of the programming capabilities of GenStat are demonstrated in Case Study 2 in which lactation yields to a fixed length are derived from 2-weekly offtake recordings and Case Study 6 in which a statistical analysis for one variable is extended to several variables.
Transformation of variables to values that follow more closely normal distributions for analysis are also easily done.
Proportions of subjects that contain a given attribute may need to be generated in multi-way tables for chi-square contingency table analysis. Alternatively, if logistic regression analysis is contemplated, numbers of 'successes' and corresponding totals may need to be determined and put into a separate spreadsheet together with factor levels. GenStat has commands that allow data to be summarised in multi-way tables. These tables can be saved and manipulated either as tables or vectors (standard form of a spreadsheet) for further analysis.
Summary descriptions of data will also be necessary (as outlined under Exploration & description for the purposes of exploring patterns in the data). These can appear as summary tables that list means, medians, ranges, standard deviations etc. or as scatter plots, bar charts or box plots etc. These facilities are available in all general statistical packages.
Residuals from a statistical model may be required to investigate their distribution. This may be to validate that their distribution is appropriate for statistical analysis. Alternatively residuals may be required for subsequent data analysis with the effects of certain model parameters removed. Case Study 2 gives an example of this in which Ankole cows are required to be ranked on the basis of milk offtake with the effect of herd removed. GenStat allows residuals to be stored in the spreadsheet alongside the original data.
As has already been described stacking and unstacking data are often required. Stacking allows blocks of variables (for example, repeated measurements in time) to be put into single columns, often to facilitate statistical analysis (Fig. 2).
The opposite, unstacking, allows data to be displayed in 'matrix' form with columns representing the repeated measurements for a given variable and rows containing the observational units. This method of data presentation provides a useful structure for monitoring purposes. Averages for each column can be calculated over rows (observational units) and the mean values used for studying changes over time.
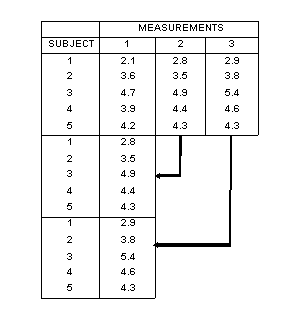
Fig. 2 Stacking of data
GenStat can also convert values stored in standard vector form into matrices, and by doing so use the matrix transpose function to convert rows into columns and columns into rows. This might be useful when one wishes to calculate the means (or some other function) of a group of observational units. Statistical programs are generally set up to apply calculations to columns rather than rows. Thus, by transposing observational units from rows to columns it becomes easier to apply the desired calculations.
Variables often need to be restricted or filtered for statistical analysis purposes in order to include only a subset of the data set defined by certain values of a factor, say. For example, Case Study 16 describes an experiment involving different planting dates of taro. It was found that yields for the 4th planting were very poor and so it was decided to do the analysis restricting the data to the first three planting dates. As shown, GenStat has simple facilities to do this. Excel has similar facilities but it is preferable to perform such functions within the package that is being used for the statistical analysis.
Facilities will also be required for appending data from one spreadsheet to the bottom of another or for merging data from two spreadsheets side by side into one. When spreadsheets are merged in GenStat columns can be specified for matching purposes. Usually this would be the identification code for observational units. Missing matches appear at the foot of the merged spreadsheet.
Most of the above data handling facilities should be available in most statistical packages. Students may be familiar with similar facilities in Excel. As already stated, however, inclusion of data management and data handling techniques in the early parts of an applied statistics course can have advantages. The student will gain greater confidence in the use of the package and have the opportunity to learn what is available without being distracted by other available software.
Individual spreadsheets become more difficult to manage when a study involves the collection of data from more than one layer (or level). The use of a comprehensive, relational database management system, such as Access or dBase, will, as already indicated, become necessary. Such data management systems are described as relational database management systems because they have built-in structures that allow links to be made to relate one data set with another. The advantage of such a system is that the full details of the study design do not need to be held at each layer, only at the top.
Although, this guide has so far promoted the concept of teaching data management using the same statistical package that is used for the analysis, such programs are inadequate for the handling multiple layered structures. In practice this does not matter because transfer of data between packages is fairly simple.
A diagrammatical illustration of the form that a multi-level data structure can take is given in Fig.3. It is assumed that data are collected at three layers: region, household, then household member. Each record at each layer has a unique identifier (indicated in parentheses in the figure). These identifiers are often described as 'key' or 'index' variables or fields.
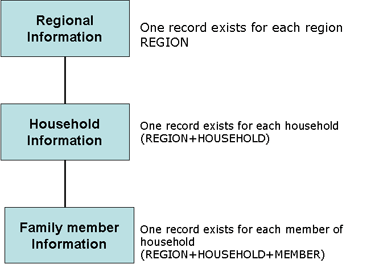
Fig.3 An illustration of the linking of multiple layers of data.
Data collected at the regional level might include a description of the agro-ecological zone, the general type of farming system applied in the region and average meteorological information such as average rainfall, temperature etc.
Data collected at each household might include the grid reference of the household, information on the number of members belonging to the household, the age and gender of the head of the household, acreage, numbers of different species of livestock, numbers of fields etc.
Within each household data may be collected on individual members of the household (such as position in household, sex, household activities engaged in, etc.) As more than one livestock species will be raised within a household, a further data layer may be required to describe which species are covered by the activities engaged in by each member of the household.
One can thus imagine a further rectangle containing the words 'Species information' under the 'Family member' rectangle.
Some of the case studies contain data that can be shown to conform to a multi-layer structure, though not all case studies required the data to be organised in a comprehensive data management system. The student should be encouraged to look at the different case studies (e.g. Case Study 6, Case Study 7, Case Study 9, Case Study 10) and describe how the data are structured and what consequences these have for the data analysis.
Case Study 11 uses a database system Breedsurv written by ILRI for the collection of livestock breed data. The student might study the way the data base has been designed to see the linkages. Four data layers can be visualised: sub-region, dip-tank area, household, member of household and, at a parallel layer with member, a series of files for each species of livestock raise in the household. The data structure is not quite of this form and the student could be asked describe how the structure was actually represented.
It would be good too for the student to describe the data structure for Case Study 11 in the form of a 'mixed model tree' as set out in Case Study 4. This case study provides another good illustration on how different layers of data are structured and how this multi-level data structure needs to be visualised when conducting a genetic analysis of lamb weaning weight.
Provided unique and simple codes for the key variables are carried down to each of the lower layers the study structure definition can be picked up at any time. A well-programmed database management system will take into account how data are to be entered and, where multiple layers of data are being entered at the same time, recall the coded key variable levels used at the higher layer to save reentry at the next.
Sometimes measurements are taken repeatedly in time from the same sampling units (e.g. Case Study 6, Case Study 10). In this case two layers, each with its own set of observational units, namely experimental subject and time when measurements were taken, can be defined. The first contains the study design with definitions of the experimental subjects and the second a set of files with details of the observations made on each subject at each sampling time. Provided that appropriate linkages are set up the only additional design variable that needs to be entered at the second layer is a code that identifies the sampling unit and the date when the observation was made.
Repeated measurement designs do not need to be held in a data management system when data are collected from a balanced controlled experiment. A well-documented series of Excel spreadsheets can be designed for such a purpose with each spreadsheet holding the data for each time point.
As should now be appreciated, one of the advantages of a relational database system is that experimental lay out details, including blocking and treatment, do not need to be repeated at each layer, only the observational unit codes. The links provided within a relational database allow data to be recalled from any layer and to be attached to the data from another layer. Similarly, definitions of the sampling frame from which a sampling unit is selected in the survey, e.g. descriptions of the region, and sub-region from which the household is selected, only need to be entered at the top layer.
Many projects are sufficiently complex nowadays that they require several linked files to hold the data (e.g. Case Study 11). Others are not. Nevertheless, when an experiment is simple and needs only a few simple spreadsheets to store the data, it is likely that the experiment may be one of a series and there will be benefit in designing a database to hold the data collected from each of them together.
One of the many advantages of a relational database management system is that it provides facilities to preserve data integrity. For example, duplicate entry of a record or entry of a record containing data inconsistent with data stored elsewhere in the database can be readily checked, something more difficult to achieve with a spreadsheet system. Data management systems can also be made more secure.
Database programming and development need not be part of a biometrics and research methods course. A researcher needs to understand how a database is constructed and thus be able to design how each file needs to be defined. Researchers may also need to know how to retrieve data but the design of a database and its construction can be the responsibility of a computer expert. Good consultation will necessarily need to be maintained with this person to ensure that he/she fully understands the project and what is to be expected from the database.
The data base management component of a biometrics course should confine itself to an understanding of data base design and methods for retrieval of data. Breedsurv, referred to in Case Study 11, contains contains various retrieval programs, known in Access as 'queries', to derive different data summaries. The student might study some of these retrievals to learn and understand methods of data retrieval in Access.
Questionnaire design has been considered in Study design, but when designing the format for the questionnaire it is also important to visualise how data entry will be done. There are various facilities that can be used in designing a data input computer screen that make data entry easy. Thus, an answer to the question: age of household <20, 21-25, 26-30, 31-40, 41-50, >50 years, can simply be entered by selecting the appropriate age range on the screen. This saves typing in the appropriate value.
It is advantageous, therefore, especially for entry of data collected from survey questionnaires, or indeed for general data input from long-term projects, to design computer screens for data entry. When a questionnaire is being designed thought needs to be given as to how well the layout lends itself to computer screen formatting.
When the format of the computer screen matches precisely the format of the questionnaire it becomes easy for a technician to enter the data. This was done for the Breedsurv system developed to handle the data described in Case Study 11. One of the screens is shown in Fig. 4. The student should compare this screen with the third questionnaire page (CS11Quest3) included with the case study.
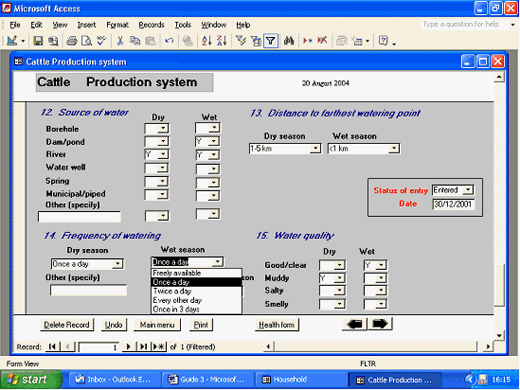
Fig.4 Example of computer data entry screen depicting different forms of data entry.
Different softwares (e.g CSPro - see Software.) are available to help to design screen layouts for data entry from questionnaires. Computer screen design is perhaps not a necessary component for a data management course in an applied biometrics course but the student should be encouraged to investigate what different software packages can do.
There is no point storing data in a database if they cannot be easily retrieved. The researcher needs to consider ahead of time the information that he/she needs to see. The query facility in the Microsoft Access software that was used for Case Study 11 enables simple summaries of data stored in the system to be viewed, reported or summarised. More complicated reports may require some programming.
Projects that continue over time (such as Case Study 6 and Case Study 10) will require some form of interim monitoring and the types of reports required should be anticipated in advance. Data handling can be a major preoccupation and it can be irritating to the researchers if reports cannot be provided as soon as new data have been entered.
Data analysis will also be required, not only at the end of the project, but also at strategic stages of the project. This can be facilitated by anticipating ahead of time the data files that will need to be retrieved and how they are to be analysed. This needs to be planned early during the data collection exercise. It may be useful to do dummy runs with partial data, including, where appropriate, any transfers of data needed between different software packages, to ensure that the output meets the required formats.
When analysing data it is preferable to extract from the original file only those data to be used for the analysis and to store them in a temporary file. If the data analysis picks up further possible data errors and it is decided to change raw data items then it is important that these should be changed in the original file (or a copy of it) and the data extracted again before continuing with the analysis.
Aspects of reporting are discussed in detail in the Reporting guide. The results required for reporting will generally be derived from computer outputs during the data analysis phase. Often, for informal reports, it may be possible to generate outputs that can be used directly for a report. For more formal research papers, however, the researcher may need to prepare fresh tables from results provided in the outputs. A good data management skill can be useful, nevertheless, in minimising the amount of work required at this stage.
It is possible to use GenStat to generate tables that can be transferred to a word processing package such as Word, and for the tables to be tidied up there. An example of this is illustrated in Case Study 2.
If the researcher can plan ahead the tables that are required for the final report, much of the basic preparation can be done during the data management and data analysis stages. Data management does not therefore end when all the data are stored and validated. By the time the researcher reaches the analytical phase he/she will have defined the primary aims for the data analysis as discussed in the Statistical modelling guide and the data handling requirements needed to achieve these aims.
Backing up and setting up audit trails can be a drag, but if a procedure for this is set up in advance it can become less of a chore. Data should be regularly backed up (or copied) onto a diskette, CD or other device. This is particularly important for long-term studies where the database is continually being updated. A suitable system of file naming should be organised so that it is clear when each back-up is made. As soon as an experiment has been completed, and all the data have been stored in a computer, a master copy should be made and again stored on diskette or CD in the event that the data kept in the computer and being used for data analysis are spoilt.
An audit trail is a type of log book which contains a complete record of changes that have been made in the data. Examples are given in Case Study 6 and Case Study 7. Just as a researcher is required to keep a note book detailing the various steps taken during his/her experiments so should notes be kept of any decisions taken during data processing. This starts with data entry and continues right through to data analysis. If changes are made to data then it should be possible to repeat the whole process from any point in the trail.
Documentation and archiving can be a tedious component of data management but they are nevertheless very important (Good practice guide No. 11). Data are expensive to collect and they may have use beyond the particular objectives of the study for which they were originally collected. A researcher therefore has a duty to ensure that his work is satisfactorily documented and archived.
Because these aspects of data management are often considered to be tedious they are often not done. However, careful planning at the start of a study can save many headaches later. When the researcher appreciates the importance of documentation and archiving at the outset then much of the work can be done during the course of the study leaving a minimum of work to be done at the end.
When a spreadsheet or a database file is being designed thought needs to be given to the form of documentation that is needed. A well written study protocol will contain much of the information that needs to be archived.
Data documentation files are included with each case study. The student needs to familiarise himself/herself with them to see how data should be documented. Case Study 3 gives a particular example showing how documentation in simple cases can be contained within the spreadsheet itself by using the top rows to give information on the variables in the columns below.
Once the data analysis has been completed and reports written, the data must be archived. This is just as important as reporting the results. Data do not belong to the individual researcher - they belong foremost to his/her institution. The institution may give permission for the researcher to access the data in future should he leave the institution, but he/she has a responsibility to ensure that a fully documented data file is lodged behind with the institution. Another researcher may wish to study the data to see what has been done, even to reanalyse them. He/she may wish to put similar sets of data together and do an overview.
The archive should include the data sets themselves, a documentation file that describes the information contained in the data sets, a copy of the original study protocol, any maps or pictures made during the study, copies of the final statistical analyses, reports or journal references, and the log book that describes what happened during the course of the experiment, during data entry and during data analysis. Hard copies of data sheets, study protocols, relevant computer outputs and reports should also be retained in the archive together with electronic versions.
A researcher is trained to keep detailed laboratory books - the same rigour needs to be applied to data recording, storage and analysis. Opportunities should be given to students to practise archiving materials from an experiment. It is better that they are taught to appreciate the importance of documentation and archiving while they are being trained, rather than expect them to pick up the knowledge once they are working.
Spatial data can be kept in a geographical information system - a specialist form of software in which values of measurements are stored together with their grid coordinates of a map. Different measurements are stored at different layers so that any can be superimposed one above each other. It is important for researchers to know the principles of such systems, to understand how data are stored and retrieved so that data can be incorporated, where appropriate, within their own studies.
Some types of information are not in a form that can be stored as data in a data file. Maps and pictures, for example, fall into this category. Modern computer scanning facilities, however, can be used to store images and these can be suitably annotated for storage on a CD. Short videos that have been taken during a study can also be stored in this way.
Much of this has already been discussed but certain key points are highlighted again.
A researcher with good computing skills may be able to handle his/her own data with little support. On the other hand 'do it yourself' data management can be very time consuming and sometimes jeopardises the success of a research project. In such cases the researcher needs to ensure that there are adequate data management skills within the research team.
In summary, treat data in the same way that you might treat money.
Ethical considerations in the analysis of data and reporting of results are described within the Reporting guide. Those that have to be borne in mind when handling data are listed here.
The reader is referred to the Good practice guides on Data management written by Statistical Services Centre University of Reading.